一、引言
一、引言
随着医疗技术的飞速发展,医疗数据的价值日益凸显。然而,由于数据孤岛、隐私保护等问题,医疗机构间的数据共享一直面临巨大挑战。医疗联邦学习平台的出现,为跨机构数据安全协作提供了新的解决方案。本文将深入探讨医疗联邦学习平台的工作原理、优势以及在实际应用中的挑战与应对策略。
二、医疗联邦学习平台概述
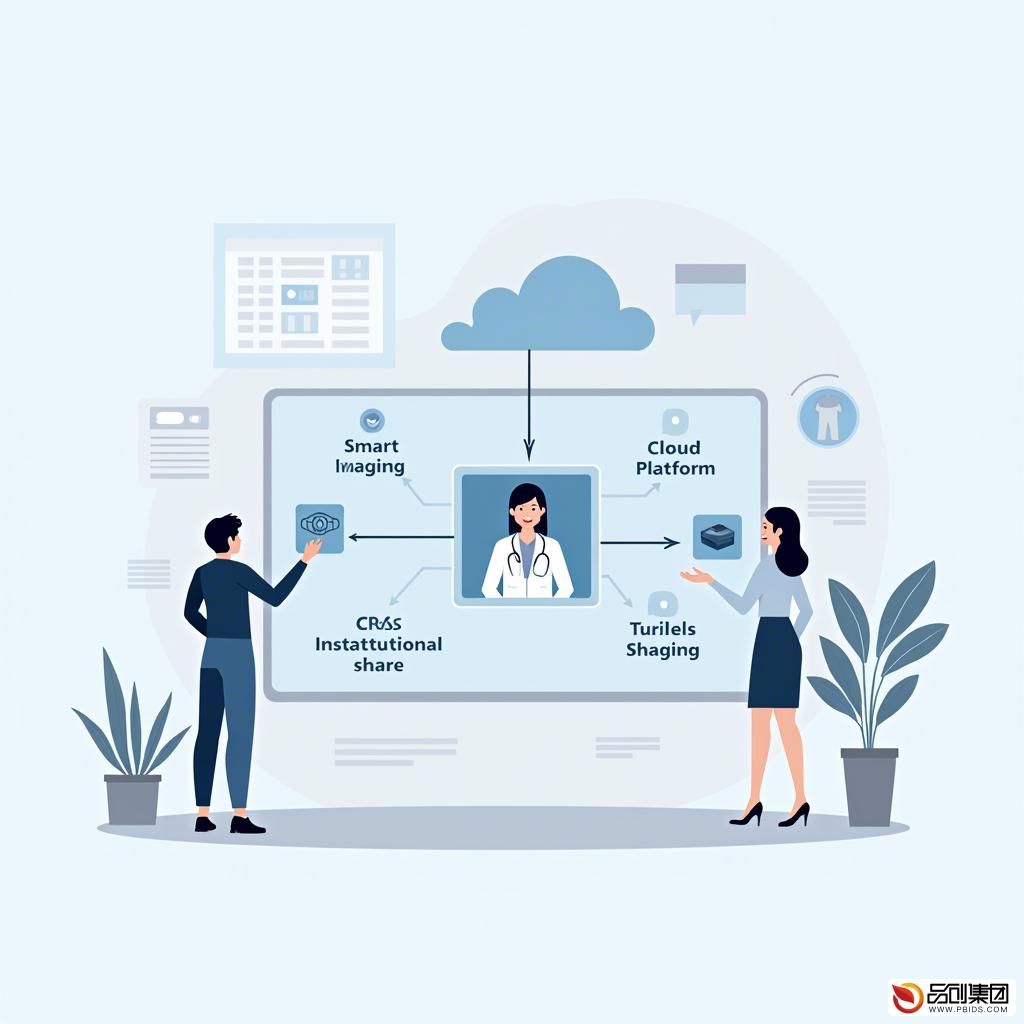
医疗联邦学习平台是一种基于分布式机器学习技术的数据协作框架。它允许多个医疗机构在不直接共享原始数据的情况下,共同训练机器学习模型。这种框架通过加密技术、差分隐私等手段保护数据隐私,确保数据在传输和存储过程中的安全性。
三、医疗联邦学习平台的工作原理
医疗联邦学习平台的工作原理主要基于以下几个步骤:
- 数据预处理:各医疗机构首先对本地数据进行预处理,包括数据清洗、特征提取等,以确保数据质量。
- 模型分发:平台将预训练的机器学习模型分发至各参与机构。
- 本地训练:各机构在本地数据上对模型进行训练,并将训练结果(如梯度更新)加密后上传至平台。
- 聚合更新:平台对收到的训练结果进行聚合,更新全局模型,并将更新后的模型再次分发至各机构。
- 迭代训练:上述过程迭代进行,直至模型收敛或达到预设的训练轮次。
四、医疗联邦学习平台的优势
- 数据隐私保护:通过加密技术和差分隐私等手段,医疗联邦学习平台能够确保数据在协作过程中的隐私性。
- 提升模型性能:跨机构的数据协作可以扩大数据集规模,提高模型的泛化能力和准确性。
- 促进医疗创新:医疗联邦学习平台为医疗AI研究提供了丰富的数据资源,有助于推动医疗技术的创新与发展。
- 降低合规成本:平台通过自动化的数据处理和隐私保护机制,降低了医疗机构在数据共享方面的合规成本。
五、医疗联邦学习平台在实际应用中的挑战与应对策略
尽管医疗联邦学习平台具有诸多优势,但在实际应用中仍面临一些挑战,如数据质量不一、通信开销大、模型训练效率低等。针对这些挑战,可以采取以下应对策略:
- 数据质量控制:建立统一的数据预处理标准和质量控制机制,确保各机构提供的数据质量一致。
- 优化通信协议:采用高效的通信协议和数据压缩技术,降低通信开销。
- 分布式训练优化:利用分布式机器学习算法和硬件加速技术,提高模型训练效率。
- 加强合规监管:建立健全的合规监管机制,确保数据共享和模型训练过程符合相关法律法规要求。
六、结论
医疗联邦学习平台为跨机构数据安全协作提供了新的解决方案,有助于打破医疗数据孤岛,提升医疗服务效率与质量。然而,在实际应用中仍需关注数据质量、通信开销、模型训练效率等问题,并采取相应策略加以应对。未来,随着技术的不断进步和应用场景的拓展,医疗联邦学习平台将在医疗领域发挥更加重要的作用。